I had also read many opinions about it, a lot of them mixed. I found Scott Hanselman's blog post introducing it interesting not for the content (though it was great as ever) but for the comments that were posted. They ranged from "this is the best thing since sliced bread" to pure venom-filled rage.
After thinking about it I did what any rational person would do - I tried it out for myself to form my own opinions. Here they are...
NuGet = Magic
The first thing of course is to download, install and integrate MiniProfiler into my web project. In the past that would have meant exactly that: 3 separate steps to perform before I could even do anything.
However, thanks to the power of NuGet, I simply installed the MiniProfiler NuGet package directly from Visual Studio. NuGet downloaded it and installed the assembly references automatically for me and all in a couple of seconds.
Any NuGet aficionados reading that last paragraph who think I sound a bit simple should be aware that this is the first time I've used it. Consider me a convert though, I can't wait to use it again.
Setup
I then followed the "Getting Started" steps from the MiniProfiler website and used the WebForms sample from their GitHub repository to plug in some boilerplate code to get it to work.
But naturally it doesn't work first time - remember, we are dealing with an open source project here! The first time I run my code I see no results "chiclet" as it is called - a little tab in the top corner of the page which you can click to see the profiling results. It just shows my webpage as it has always looked.
After some Googling around and searching on StackOverflow I found out that I had missed this important setting from my web.config file:
This setting was missing because we recently upgraded our WebForms project to .NET 4 and this setting apparently is provided by default in new projects. With this enabled I finally see this:

<system.webServer> <modules runAllManagedModulesForAllRequests="true"/> </system.webServer>
This setting was missing because we recently upgraded our WebForms project to .NET 4 and this setting apparently is provided by default in new projects. With this enabled I finally see this:
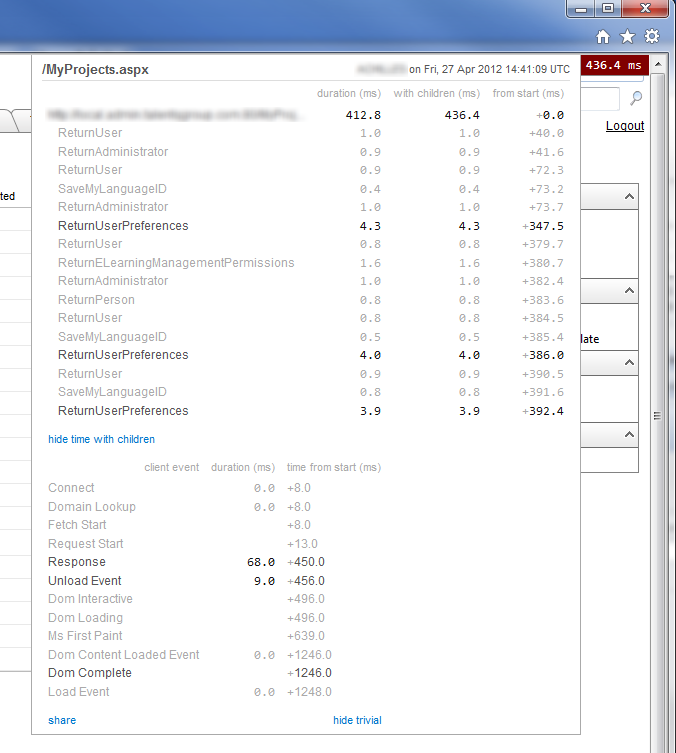
Profiling your Code
Now that everything is set up, I can start profiling code. The rationale behind MiniProfiler is to find areas that you think could perform better and then start adding
using blocks around your code to record timings, like this:private void MyLongRunningFunction()
{
using (MiniProfiler.Current.Step("Profiling my code"))
{
// Your code goes here, then timings appear in the results
// tab as "Profiling my code"
}
}
This seems to annoy a lot of people, their argument being that they shouldn't be making their code "ugly" just to do some simple profiling. My opinion on the matter is:
- I've seen far uglier code than this.
- You don't have to put these blocks of code everywhere, just the areas you want to inspect, and
- Once you've finished profiling and if it really bothers you, why not just remove them?
Profiling your Database
Now this is where I do have a bone of contention with the MiniProfiler developers. But first let me give some context.
At work we use stored procedures for all our database calls, no inline SQL. We then have a data-access layer which basically has a class method mapped to each stored procedure using standard ADO.NET code (raw
So I wasn't that impressed when I read what was said about integrating database profiling with MiniProfiler. Quoted from their website:
Unfortunately database profiling is something I really wanted as my gut instinct tells me that is where a lot of our performance bottlenecks could be. Having pondered on the situation I decided to compromise by wrapping our ADO.NET code within a

SqlConnection and SqlCommand objects). Overall we must have hundreds of these methods throughout this layer. Sometimes it's not perfect but overall I'm happy with the way it works and see no reason to change it.So I wasn't that impressed when I read what was said about integrating database profiling with MiniProfiler. Quoted from their website:
The profiler includes powerful and comprehensive database profiling capabilities. To enable wrap your database connection with a profiling connection.Basically they are suggesting I re-write a lot of my data-access code to facilitate this library, which I disagree with: this library is meant to fit around my needs, not the other way around.
Unfortunately database profiling is something I really wanted as my gut instinct tells me that is where a lot of our performance bottlenecks could be. Having pondered on the situation I decided to compromise by wrapping our ADO.NET code within a
using/timing block to achieve a similar effect - in fact, I posted an explanation of what I did on this StackOverflow question. I imagine that I am losing some benefits from my approach, but at least I can see which stored procedures are called on each request and can see how long they are taking to complete.
The timings highlighted are stored procedure calls taken from being wrapped around simple Step() profiler calls.
Conclusion
It took me a couple of hours to get everything working but it has resulted, at the very least, in showing me that we do a lot of duplicate database calls which are unnecessary. I'm looking forward to finding the slowest parts of our code (which I know are there) and seeing how we can optimise them.
Regarding my opinions on MiniProfiler itself, I'm not entirely sure why the detractors make such a fuss over it. Yes it is quite basic as a profiler and doesn't cover all your running code like some professional tools would, but what do you expect for something that is free to use?
Having some issues around database profiling I can also appreciate why some people would not want to alter their code just to get a pretty profiling page appear on their website. Personally, although the MiniProfiler developers sell it as something you can run in a live environment, I see it as more of a testing/debugging aid mainly for use in our development environment. It might be interesting to see how a real server setup affects the outcomes of things but ultimately I think I will use this during development on our code/stored procedures.
Regarding my opinions on MiniProfiler itself, I'm not entirely sure why the detractors make such a fuss over it. Yes it is quite basic as a profiler and doesn't cover all your running code like some professional tools would, but what do you expect for something that is free to use?
Having some issues around database profiling I can also appreciate why some people would not want to alter their code just to get a pretty profiling page appear on their website. Personally, although the MiniProfiler developers sell it as something you can run in a live environment, I see it as more of a testing/debugging aid mainly for use in our development environment. It might be interesting to see how a real server setup affects the outcomes of things but ultimately I think I will use this during development on our code/stored procedures.
